Những tác vụ tạo hình ảnh bằng trí tuệ nhân tạo đang được rất nhiều khách hàng quan tâm tìm hiểu. Hai trong số những hệ thống nổi bật trong công nghệ này là DALL-E và Stable Diffusion. Cả hai đều có khả năng tạo ra hình ảnh chất lượng cao từ văn bản, nhưng lại khác nhau về kỹ thuật, cách tiếp cận và ưu nhược điểm riêng.
Trong bài viết này, Nhật Minh chia sẻ chi tiết hai công nghệ để giúp bạn hiểu rõ hơn về cách mỗi hệ thống hoạt động và ứng dụng của chúng trong thực tế.

Bộ đôi tạo hình ảnh Ai hot nhất thời điểm hiện tại
DALL-E là một sản phẩm của OpenAI, tổ chức nổi tiếng với các công nghệ AI tiên tiến. DALL-E được xây dựng dựa trên nền tảng của GPT-3, một mô hình AI chuyên về ngôn ngữ tự nhiên. Với cơ chế học sâu, DALL-E được huấn luyện trên một lượng lớn dữ liệu kết hợp giữa văn bản và hình ảnh để học cách chuyển đổi mô tả ngôn ngữ thành hình ảnh tương ứng. Điều này cho phép hệ thống có thể nắm bắt và chuyển đổi các mô tả phức tạp, từ đơn giản đến siêu thực, thành hình ảnh sống động.
DALL-E hoạt động dựa trên kiến trúc Transformer, vốn là công nghệ nền tảng cho GPT-3 và nhiều hệ thống AI hiện đại. Kiến trúc này cho phép DALL-E xử lý khối lượng dữ liệu khổng lồ, với hàng tỷ tham số được huấn luyện để liên kết ngôn ngữ và hình ảnh. Dữ liệu huấn luyện bao gồm một tập hợp lớn các cặp văn bản-hình ảnh, từ đó mô hình có thể "học" cách tái tạo hình ảnh từ mô tả văn bản.
Kích thước mô hình: DALL-E sử dụng hàng tỷ tham số, tương tự như GPT-3, để tạo ra hình ảnh phức tạp và có độ chi tiết cao.
Dữ liệu huấn luyện: Được huấn luyện trên một lượng lớn dữ liệu văn bản và hình ảnh, giúp mô hình hiểu được cách chuyển đổi từ ngôn ngữ thành hình ảnh một cách chính xác.
Khả năng tạo ảnh: DALL-E có khả năng tạo ra hình ảnh với độ phân giải cao và chi tiết phong phú, ngay cả từ các mô tả văn bản rất trừu tượng.
Công cụ từ OpenAi
DALL-E sử dụng thuật toán Transformer, vốn được biết đến với khả năng xử lý ngôn ngữ tự nhiên và tạo văn bản. Trong quá trình tạo hình ảnh, DALL-E trước tiên phân tích văn bản để chuyển đổi mô tả thành các vector ngữ nghĩa. Những vector này sau đó được sử dụng để tạo ra hình ảnh thông qua một mạng nơ-ron tạo hình ảnh chuyên dụng. Quá trình này cho phép DALL-E tạo ra hình ảnh chân thực và chi tiết dựa trên mô tả của người dùng.
Trong khi DALL-E nổi bật với việc sử dụng mô hình ngôn ngữ GPT-3 để tạo hình ảnh, Stable Diffusion sử dụng một phương pháp hoàn toàn khác. Đây là một mô hình học sâu áp dụng thuật toán diffusion (khuếch tán), một cách tiếp cận mang tính cách mạng trong việc tạo hình ảnh từ các điểm ảnh ngẫu nhiên. Stable Diffusion bắt đầu từ một tập hợp các điểm ảnh ngẫu nhiên và dần dần chuyển đổi chúng thành hình ảnh hoàn chỉnh dựa trên mô tả văn bản.
Mặc dù không sử dụng hàng tỷ tham số như DALL-E, Stable Diffusion vẫn đạt được hiệu suất ấn tượng nhờ vào thuật toán độc đáo của mình. Mô hình này yêu cầu ít tham số hơn nhưng vẫn có khả năng tạo ra các hình ảnh có độ chi tiết và độ chính xác cao.
Kích thước mô hình: Stable Diffusion sử dụng ít tham số hơn DALL-E nhưng vẫn đảm bảo hiệu suất cao nhờ thuật toán diffusion.
Dữ liệu huấn luyện: Mô hình cũng được huấn luyện trên một tập dữ liệu lớn chứa các hình ảnh và mô tả liên quan để học cách chuyển đổi từ văn bản thành hình ảnh.
Khả năng tạo ảnh: Stable Diffusion cho phép kiểm soát tốt hơn các yếu tố hình ảnh như ánh sáng, bóng đổ và cấu trúc hình ảnh, tạo ra các hình ảnh chất lượng cao.

Công cụ từ OpenAi
Stable Diffusion sử dụng thuật toán khuếch tán, bắt đầu từ một tập hợp các điểm ảnh ngẫu nhiên. Quá trình này từ từ điều chỉnh và biến đổi các điểm ảnh dựa trên mô tả văn bản để tạo ra hình ảnh hoàn chỉnh. Đây là điểm nổi bật của Stable Diffusion so với DALL-E. Trong khi DALL-E tạo hình ảnh trực tiếp từ văn bản, Stable Diffusion trải qua một quá trình khuếch tán các điểm ảnh từ thô sơ đến hoàn thiện, cho phép kiểm soát chi tiết hơn về cấu trúc và ánh sáng.
Cả DALL-E và Stable Diffusion đều có khả năng tạo ra hình ảnh chi tiết, nhưng mỗi hệ thống lại có thế mạnh riêng. DALL-E nổi bật với khả năng nắm bắt các mô tả phức tạp và thể hiện chúng thành hình ảnh sinh động. Hệ thống này có thể tạo ra các hình ảnh chi tiết từ những mô tả siêu thực hoặc khó hiểu.
Ngược lại, Stable Diffusion lại mạnh mẽ trong việc kiểm soát các yếu tố thị giác như ánh sáng và bóng đổ. Điều này giúp mô hình này tạo ra các hình ảnh có độ chính xác cao và giàu tính nghệ thuật. Những dự án yêu cầu độ tinh tế về màu sắc, cấu trúc hình ảnh thường sẽ phù hợp hơn với Stable Diffusion.

Một điểm khác biệt quan trọng giữa hai công nghệ này là nền tảng hoạt động. DALL-E được triển khai trên nền tảng đám mây (cloud), vì vậy người dùng không cần cấu hình máy tính, Laptop quá mạnh để sử dụng. Điều này rất thuận tiện cho những ai không có thiết bị mạnh mẽ nhưng vẫn muốn tận dụng khả năng tạo hình ảnh của AI.
Trong khi đó, Stable Diffusion hoạt động chủ yếu trên máy cục bộ (local), đòi hỏi người dùng phải có kiến thức kỹ thuật và máy tính cấu hình cao để vận hành mô hình này. Điều này có thể làm giới hạn khả năng tiếp cận của người dùng phổ thông, nhưng lại mang lại sự linh hoạt và khả năng tùy biến cao cho những ai có đủ kỹ năng và công nghệ.
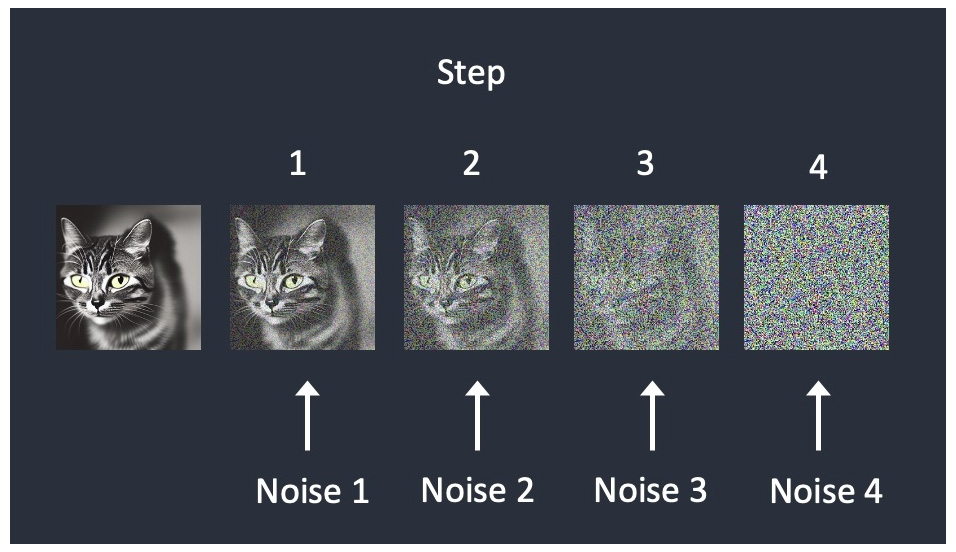
Stable Diffusion cần đòi hỏi máy có cấu hình cao
DALL-E và Stable Diffusion đều là những công nghệ tiên tiến trong lĩnh vực tạo hình ảnh từ văn bản, mỗi mô hình có những ưu điểm và nhược điểm riêng.
DALL-E phù hợp cho những ai muốn tạo ra hình ảnh từ các mô tả phức tạp và không cần quá nhiều kiến thức kỹ thuật, nhờ vào nền tảng cloud dễ sử dụng.
Stable Diffusion lại là lựa chọn tốt cho những dự án đòi hỏi độ chi tiết cao về ánh sáng và cấu trúc hình ảnh, nhưng yêu cầu người dùng phải có máy tính mạnh và hiểu biết về vận hành mô hình AI.
Nhật Minh Laptop sẵn sàng hỗ trợ bạn trong việc lựa chọn mô hình nào phù hợp với nhu cầu cụ thể của từng dự án, đảm bảo rằng bạn có thể tận dụng tối đa sức mạnh của AI trong công việc của mình.
P/s: Tham khảo Laptop Dell XPS 13, 14, 16 Core Ultra mới nhất, Giá tốt
![]()
P/s: Máy Trạm đồ họa chuyên nghiệp, cấu hình khủng, CPU tích hợp AI

P/s: Laptop Dell Latitude xách tay, giá tốt

Tham khảo thêm:














 Laptop
Laptop
 Macbook
Macbook